What 24 algorithms revealed
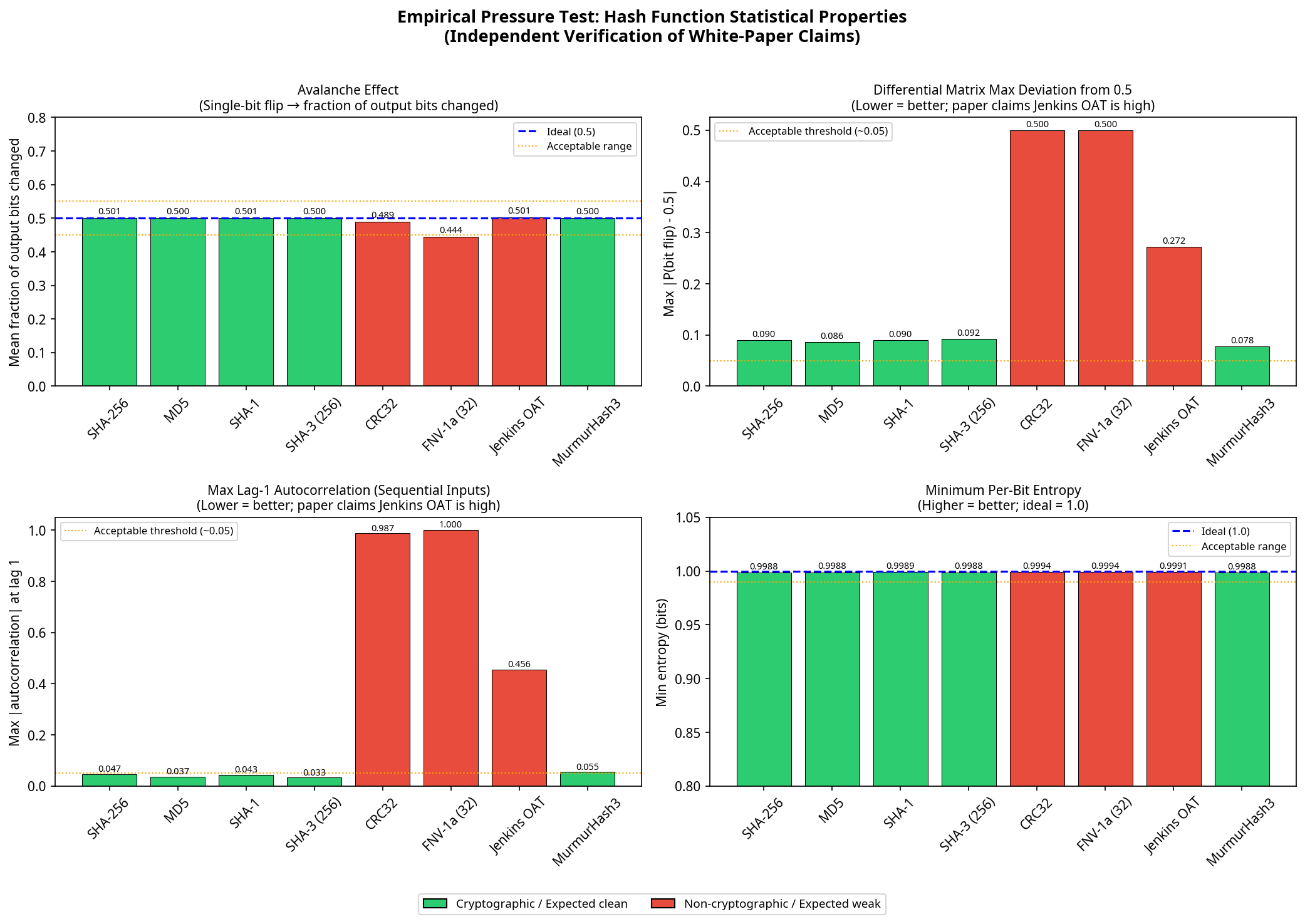
All 15 cryptographic algorithms tested — including SHA-256, AES-128, SM3, BLAKE2b, and ChaCha20 — produced output statistically indistinguishable from a perfect random oracle at 100,000 samples. The non-cryptographic hashes told a different story.
Jenkins OAT: The Hidden Weakness
Jenkins one-at-a-time is widely used in hash tables. It passes every aggregate statistical test — bit correlation, entropy, avalanche, frequency, mutual information. The meta-learner classifies it as clean (P = 0.15). But differential profile analysis tells a different story.
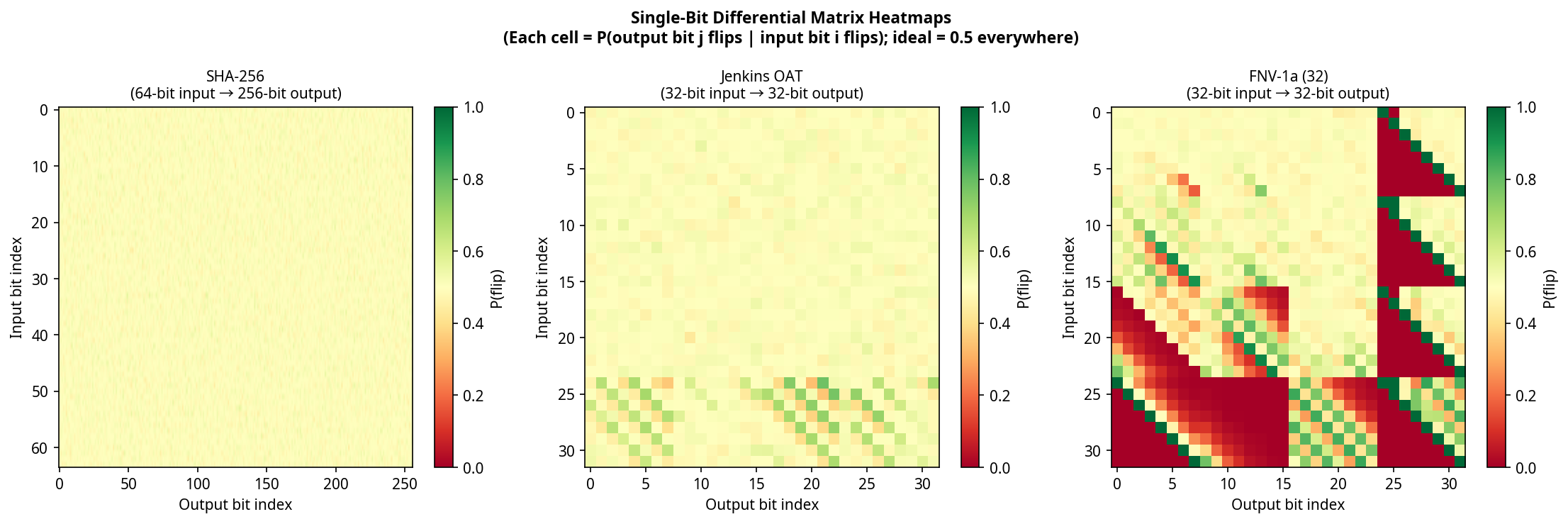
Its single-bit differential matrix shows significant non-uniformity (signal strength: 1.000), and sequential outputs exhibit high autocorrelation. The structural reason: Jenkins' shift-and-add construction has no final mixing pass, creating position-dependent differential structure in the last input bytes.
CRC32: Algebraic, Not Statistical
CRC32's XOR-linearity is algebraic — not statistical. The aggregate suite classifies it as clean (P = 0.11). But differential and sequence correlation tests detect it immediately, confirming that different methods catch different categories of weakness.
SHA-3 vs. SHA-1: Diffusion Rates
SHA-3's sponge construction achieves full 1600-bit state diffusion in just 3 of 24 rounds. SHA-1 requires 20 of 80 rounds to reach 90% diffusion. SM3 achieves nearly double SHA-256's early-round diffusion rate — a deliberate design choice by its authors.
MurmurHash3 & SipHash: Clean
Neither claims cryptographic security, yet both are completely clean across all seven detection methods — indistinguishable from random oracle controls. Statistical quality is a design choice, not an inherent property of complexity.
Independent Verification
These visualizations were generated by independently re-implementing the paper's core methodology — not by running the tool itself. The results confirm the paper's findings from scratch.